Enhancing model training with differential privacy
Applying differential privacy to synthetic data for stronger privacy protection
Privacy in machine learning is a critical concern, especially when training models on sensitive data. Differential Privacy (DP) provides a robust framework to quantify and limit the amount of information a model can reveal about any training data point. In this post, we explore how DP is used in model training, what makes synthetic data differentially private, and how DP is applied to synthetic data generation within aindo.rdml.
What is differential privacy?
Differential Privacy (DP) ensures that the inclusion or exclusion of any single data point in a dataset used for training does not significantly alter the output of a machine learning model. Let’s consider two scenarios:
- Scenario A: the dataset used to train the model contains data point x.
- Scenario B: the dataset used to train the model does not contain data point x.
Differential privacy guarantees that the difference in the model’s output between these two scenarios remains within a defined threshold, which determines the level of privacy protection. As a result, it is impossible to infer whether x was included in the training dataset simply by analyzing the output. In this way, the differentially private algorithm protects the privacy of the individual’s data.
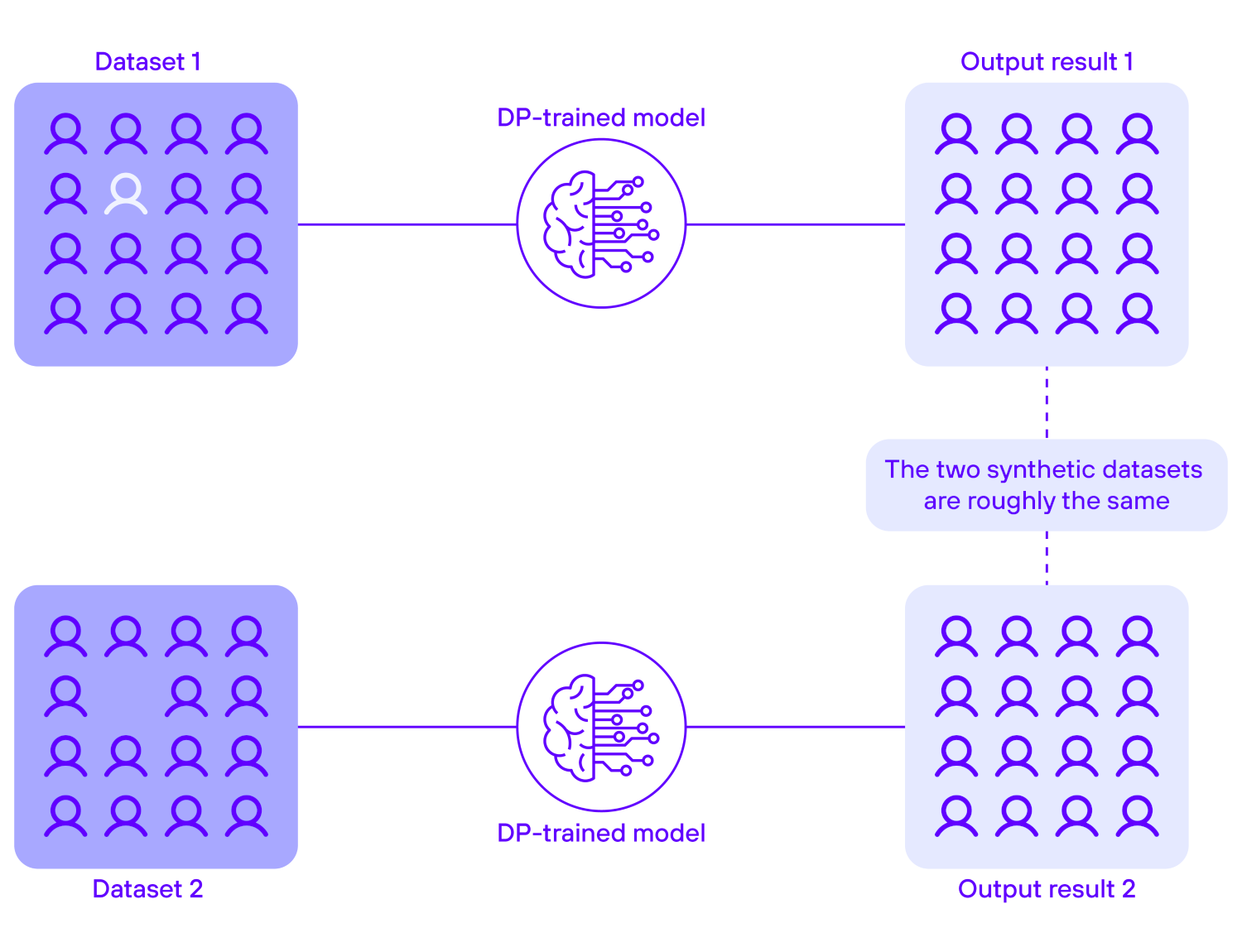 The training datasets in scenario A (top) and scenario B (bottom) differ by a single datapoint but yield the same
results. Just by looking at the output it is impossible to determine whether the datapoint was or was not included
in the training dataset.
The training datasets in scenario A (top) and scenario B (bottom) differ by a single datapoint but yield the same
results. Just by looking at the output it is impossible to determine whether the datapoint was or was not included
in the training dataset.
Differential privacy for synthetic data model training
When applied to generative model training for synthetic data, DP limits how much influence any individual data point can have on the resulting synthetic data. Differentially private synthetic data is data generated through a DP-preserving algorithm. This means that even if an attacker has access to both the model and its synthetic outputs, they cannot determine whether a specific record was used during training.
An added advantage of DP is its post-processing property: we can perform any operations on the differentially private synthetic data but we can’t undo the effect of DP. This property is mathematically proven, meaning that even future technological developments will not allow adversaries to undo the effects of DP. This is particularly significant in the context of GDPR, which states that data cannot be considered anonymous if it may be re-identified with future technologies.
How Aindo applies differential privacy to model training
Training a deep learning model with DP is not trivial. At Aindo, we have integrated several features in our platform that ensure rigorous DP guarantees at every stage:
- Noisy gradients: During training, carefully calibrated noise is added to the gradients to obscure the contributions of individual data points.
- Poisson sampling: Instead of splitting the training data into equal sized subsets, at each training step, each data point is selected for inclusion in the current batch with probability described by a Bernoulli distribution.
- Privacy accountant: Privacy accounting methods are used to track cumulative privacy loss over multiple training iterations, ensuring that the final model adheres to the chosen parameters.
- Early stop procedure: Training halts when the relative variation in validation loss falls below a defined threshold, preventing overfitting while maintaining DP guarantees.
DP in aindo.rdml
In aindo.rdml, we provide an option to train generative models in a differentially private fashion. This ensures that synthetic data generated through our platform retains strong privacy guarantees while preserving analytical utility.
To learn more about how aindo.rdml applies DP to synthetic data generation, check out our documentation.
Differential privacy alone is not enough
While DP is a powerful tool for protecting sensitive data, it does not guarantee privacy if other vulnerabilities exist in the pipeline. For example, if personally identifiable information is incorrectly configured as categorical at the start, the output can leak privacy even if DP is applied during training.
Differential privacy should always be combined with other best practices in data security and anonymization. The application of DP must be done carefully, ensuring that its guarantees remain intact at each step of model training and deployment.
Trust the experts
Applying differential privacy correctly requires deep technical expertise. At Aindo we specialize in cutting-edge privacy-preserving AI solutions and have built a robust synthetic data platform where DP is applied in an easy and seamless way. Contact us today to see how differential privacy and synthetic data can unlock new possibilities for your organization.


